Querying Elasticsearch
One of the many things I like about Elasticsearch is its JSON-based domain-specific language (DSL). For example, a simple search query looks like this:
{
{
"from": 0,
"size": 10,
"query": {
"query_string": {
"query": "banana"
}
}
}Kimchy could have created a SQL-like query language for Elasticsearch, in which case the query above would probably look somewhat like this:
query (query_string = "banana") with from(0), size(10)Fortunately, he didn't. Let me explain why I think that was a particularly smart choice.
Going back to SQL and relational databases for a second. As a developer, one of the design choices you might still have to make is whether or not to use an object-relational mapper (ORM). Yes, it's been 10 years since ORMs have famously been called The Vietnam of Computer Science, and yes, we live in NoSQL times (in fact, Elasticsearch itself supposedly makes an excellent NoSQL data store now). Meanwhile in the real world (ya know, enterprises and such), relational databases and ORMs are alive and doing well.
Anyways - should you choose to actually use an ORM on top of your relational store, you've just introduced an additional layer of abstraction (what did Joel say about those again?). If you're going down the no-ORM route on the other hand, you're likely to fiddle with raw strings in your code at some point, which can get messy. And, even if your language is statically typed, the compiler won't type-check anything for you.
In the .NET world, @Mpdreamz' excellent NEST library is what I would consider the equivalent of an ORM, with similar pros (static type checking, code completion) and cons. If you want to go no-ORM here to avoid the extra layer of abstraction, you still won't have to fiddle with raw query strings, ever - thanks to the fact that the query DSL is JSON-based, serializing anonymous classes does the job for you:
var page = 1;
var pageSize = 10;
var searchText = "banana";
var queryObject = new
{
from = (page - 1) * pageSize,
size = pageSize,
query = new
{
query_string = new { query = searchText }
}
};
var queryString = JsonConvert.SerializeObject(queryObject); // JSON.NETCase in point: last week, I rewrote a fairly complex search query. It's the one that finds companies (more precisely, company pages) if you hit up search on Stack Overflow Careers:
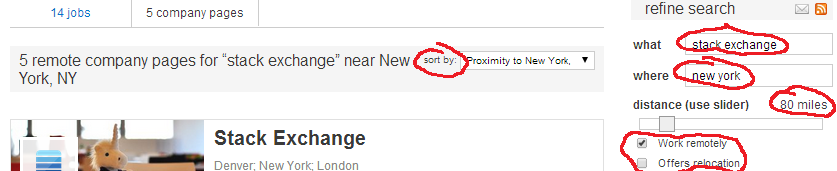
Well, maybe it's not that complex, but some of the pieces are a little bit tricky: depending on the search parameters, results need to be geo-filtered in various ways. Sorting of results depends on other factors, such as the number of search terms, and the physical location of the user. Then, there's paging of results. Finally, we're also throwing in a term suggestor to check for similarly spelled search terms.
To me, dynamically composing and troubleshooting the query was much easier and straightforward once I switched from statically typed helpers to serialized anonymous classes. They are very close to the actual raw JSON, so you can easily copy&paste snippets, run and troubleshoot them directly on Elasticsearch, and then go back to your code and make fixes as necessary. No "translation" needs to happen anymore between the world of "raw" queries and a statically typed client library.
The compiler won't be able to check if what you're producing is a valid Elasticsearch query - for that, you want to create integration tests. However, unlike when fiddling with raw strings (like you would do with SQL queries), it will most of the time prevent you from producing syntactically invalid JSON.
So, this is how I will build all my Elasticsearch queries from now on. If only there was a similar JSON-based query language for my relational data store as well...